El Ayadi M, Kamel M S, Karray F. Survey on speech emotion recognition: Features, classification schemes, and databases[J]. Pattern Recognition, 2011, 44(3): 572-587.
简介
语音识别的发展可以说是非常成熟,但距离我们的目标——自然的人机交互,还差的很远,这其中的一个原因就是现在机器还无法理解我们说话时的情感。这是研究语音情感识别的一个重要的motivation。
情感识别的用处
- 自然的人机交互(natural man-machine interaction)。
- 车载系统(in-car board system)。用于检测司机的精神状况以确保驾驶安全。
- 。。。
情感识别面临的挑战
- 什么样的特征在分辨情感中最有用。
- 一个发音中可以会包含多种感情,不同情感的边界也难以界定,哪个情绪是当前主导的情绪?
- 表达情感是一个个性化极强的事情,根据个人,环境甚至文化差异都很大。
- 情绪可能持续很长时间,但期间也会有快速变化的情绪,情感识别系统是检测长期的情绪还是短时的情绪了(比如被炒鱿鱼了,会悲伤很久,但这期间吃了顿好吃的饭,虽然会开心,但人还处在伤心的状态中,那么该判定为悲伤还是开心呢)。
- 情感本身都难以明确的定义。
情感
虽然情感本身十分复杂,但一个被广泛认同的模型是讲情感划分为两个维度:activation 和 valence。activation指得是表达这个情感需要的能量。比较强烈的情感比如愤怒,喜悦,恐惧。伴随着这类感情可能会有心跳加速,血压升高等等,同时人的语速会变快,音高变高。相反比较舒缓的请看比如忧伤,语速可能会降低,高频会减少。而activation类似的感情,比如愤怒与喜悦,则用valence来加以区分。用何种feature来描述valence尚无定论。因此,在情感识别系统中,强烈的感情与舒缓的感情很好区分,而区分不同类别的情感则还是一个挑战。
语音情感识别中的特征
特征提取是模式识别任务中最重要的一个环节之一,在语音情感识别的任务中亦然。我们会面对四个主要的问题
- 特征提取的作用域。是对音频进行分帧(frame)再提取特征,或是对全局进行提取?
- 提取什么样的特征?
- 是否要进行前处理与后处理?比如移除静音的部分。
- 要不要结合其他的特征?比如语言模型或者面部表情。
对以上四个问题的分析
局部特征还是全局特征
全局特征在分类的准确率上往往比局部特征表现的要好,同时耗时也更少(特征量较少)。然而全局特征也有许多缺点:
- 只在分类高兴奋度的情感(high-arousal emotions,也是我们之前说的activation较高的情感)中比较有效,比如在分类anger和joy时,全局特征就会失效。
- 全局特征会丢失语音的短时信息(temporal information)。
当使用较为复杂的分类器(HMM,SVM等)时,全局变量会因为特征较少而无法进行有效的训练。
因此在复杂的模型中使用局部特征,模型的准确率更好。
还有一种做法是对语音信号根据音素进行分段而不是分帧。研究显示了把分段的特征和全局特征相结合可以一定程度提高是别的准确率。
提取什么样的特征
我们可以把语音特征划分为四类:
- Continuous speech features 连续语音特征
- pitch-related features
- formants features
- energy-related features
- timing features
- articulation features
常用的有F0,Energy,Duration,Formants。另外在特征的提取中,除了使用特征还对特征进行一些转换,比如平均,最大最小等。在INTERSPEECH 2009 中有个图表就很清晰的展示了这一点。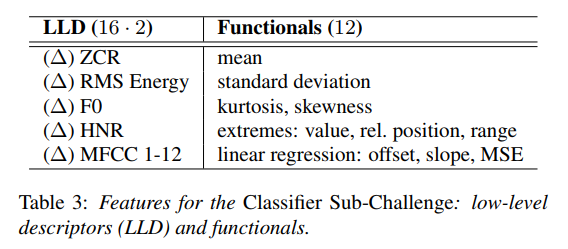
对于每一帧信号,我们提取16个特征和它们的delta,并对这32个特征进行右边的12种变换,得到384维((16x2)x12)的特征向量(每一帧)。
- Voice quality features
- voice quality
- harsh
- tense
- breathy
- Spectral-based speech features
- LPC
- MFCC
- LFPC
TEO-based features
小结:Continuous speech features 用来检测high-arousal和low-arousal的情感;频谱特征比如MFCC用来做N-way classification的问题,TEO-based features 用于压力检测;
- Continuous speech features 连续语音特征
语音处理
- 前处理
- pre-emphasis filter, $H(z)=1-0.97z^{-1}$: to equalize the effect of the propagation of speech throungh air.
- overlapped frames: to smooth the extracted contours.
- Hamming window: to reduce ripples in the spectrum of the speech spectrum.
- slient intervals: 语音中的静音间隔也包含情感信息,通常会保留下来。
- 特征提取
- 后处理
- 正规化 feature normalization
- $\hat{x}=\frac{x-\mu}{\sigma}$
- 重要!但由于方差中包含许多情感信息,normalize后会消除这些特征,要考虑到这一点。
- 降维
- feature selection:找到分类效果最好的子特征。
- feature extraction:对原始特征进行mapping到另一空间,从而达到降维效果。
- 正规化 feature normalization
- 前处理
声学特征与其他特征结合
- 语言信息(linguistic information)
- 视频信息
分类方法
都是些大家熟悉的手法。
- HMM:效果好(在语音情感识别的任务里,正确率甚至可能超过人类)
- GMM:比HMM高效,但不能利用短时特征
- Neural networks:emmm。。大家都在用
- SVM
- Multiple classifer system
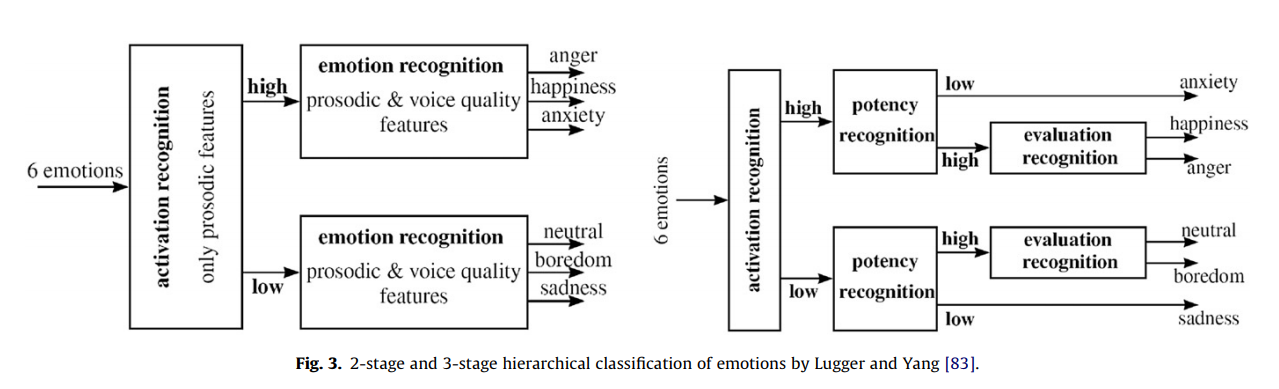
这个比较有趣,可以把情感识别分几步来做,比如先分类 high arousal 和 low arousal 的情感,再进行子类别的分类可以看这个图。